現在の大規模言語モデルは数学計算において克服困難な欠陥を抱えており、重要業務での応用を妨げています。
基本的な数学問題(GSM8Kなど)でさえ、LLMは100%の正解率を保証できません。金融、医療、産業などの分野では、わずかな誤りでも深刻な結果を招く可能性があります。
思考連鎖(CoT)や報酬モデルなどの強化手法は、トークン消費量と応答時間(数倍から数十秒)を大幅に増加させ、計算コストを急増させます。
コードインタプリタ(Pythonなど)の統合は、セキュリティ上の脆弱性(インジェクション攻撃)をもたらし、モデルがコードを理解・生成する複雑性を増大させます。
これらの欠陥により、企業は正確な計算が必要なコア業務においてLLMを信頼し、広く活用することができません。
LLMの「推論」能力と専門計算エンジンの「計算」能力を革新的に分離し、相互補完を実現します。
このアーキテクチャは、LLMの計算に関するジレンマを根本的に解決し、重要なビジネスアプリケーションへの道を開きます。
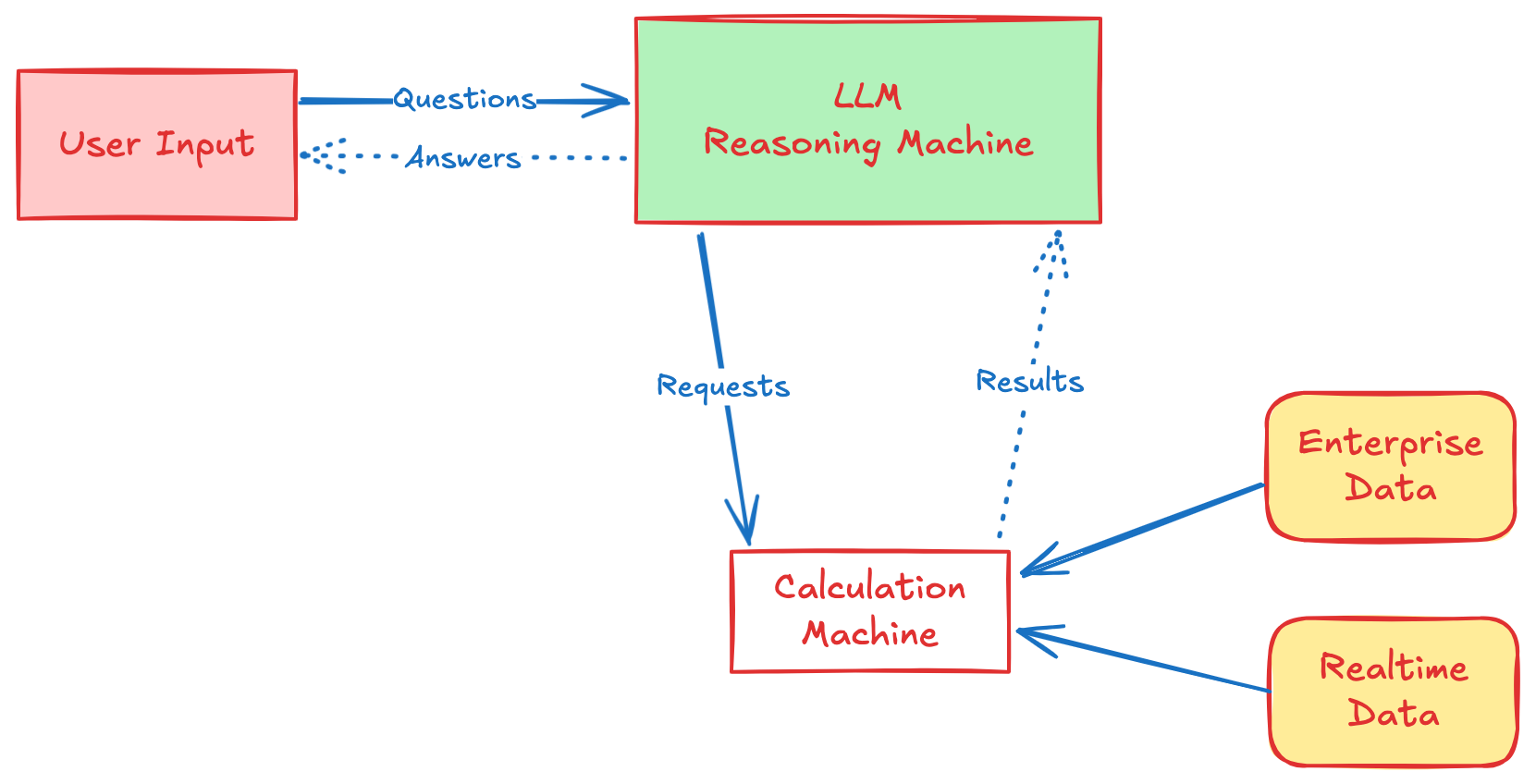
「推算分離」アーキテクチャは、LLM計算能力に対する企業の4つの主要な要求に完全に対応します。
外部の専門エンジンにより計算を実行し、結果の100%の正確性、信頼性、一貫性を確保。確率モデルの不確実性を排除します。
計算エラーはLLMが生成した数式段階に明確に特定され、モデルの理解や推論の偏りを容易に診断できます。
ファインチューニングやプロンプト調整などにより、モデルの数式生成能力を的を絞って改善し、問題を迅速に修正できます。
高速応答(平均2秒)、トークン消費量50%削減、コスト管理可能、大規模展開が容易、スムーズなユーザーエクスペリエンス。
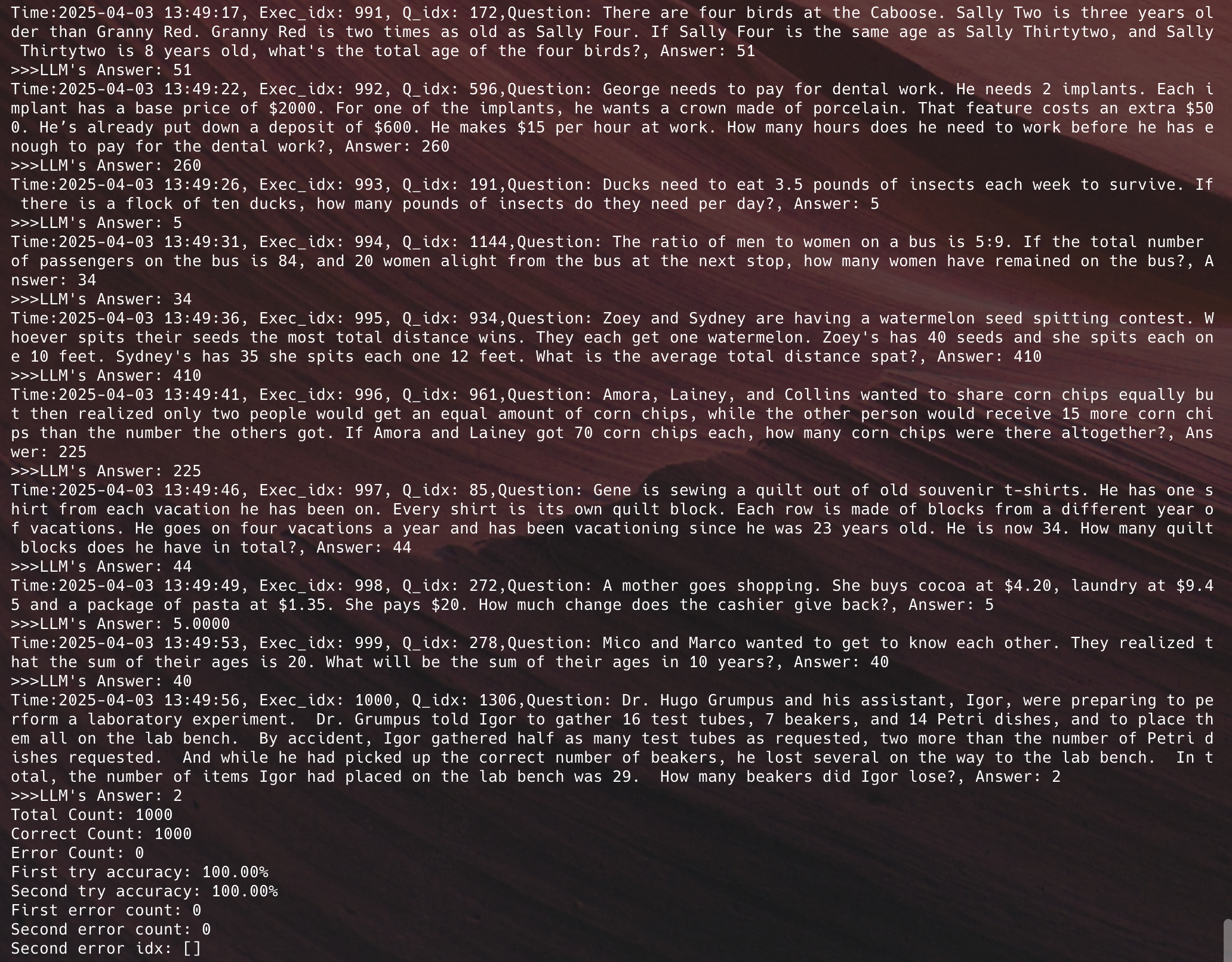
Qwen2.5-72Bとローカルの専門計算エンジンに基づき、GSM8Kベンチマークで画期的な成果を達成しました。
>97% 初回出力正解率
>98% 2回目出力正解率
手動調整後 100%達成可能
平均応答時間:2秒
トークン消費量 50%削減
初等代数演算
行列演算
微分方程式
畳み込み計算など
「推算分離」が、重要業務においてLLMを安全、確実、効率的に活用するのにどのように役立つかをご覧ください。カスタマイズされたソリューションや製品デモについては、今すぐお問い合わせください。