当前大语言模型在数学计算方面存在难以克服的缺陷,阻碍其在关键业务中的应用。
即使是基础数学题(如GSM8K),LLM也无法保证100%正确。在金融、医疗、工业等场景,微小的错误都可能导致严重后果。
思维链(CoT)、奖励模型等增强方法,大幅增加Token消耗和响应时间(数倍至数十秒),算力成本激增。
集成代码解释器(如Python)引入安全隐患(注入攻击),并增加了模型理解和生成代码的复杂性。
这些缺陷导致企业无法信任并广泛应用大模型于需要精确计算的核心业务。
我们创新性地将大模型的“推理”能力与专业计算引擎的“计算”能力分离,实现优势互补。
这种架构从根本上解决了大模型的计算困境,为关键业务应用铺平了道路。
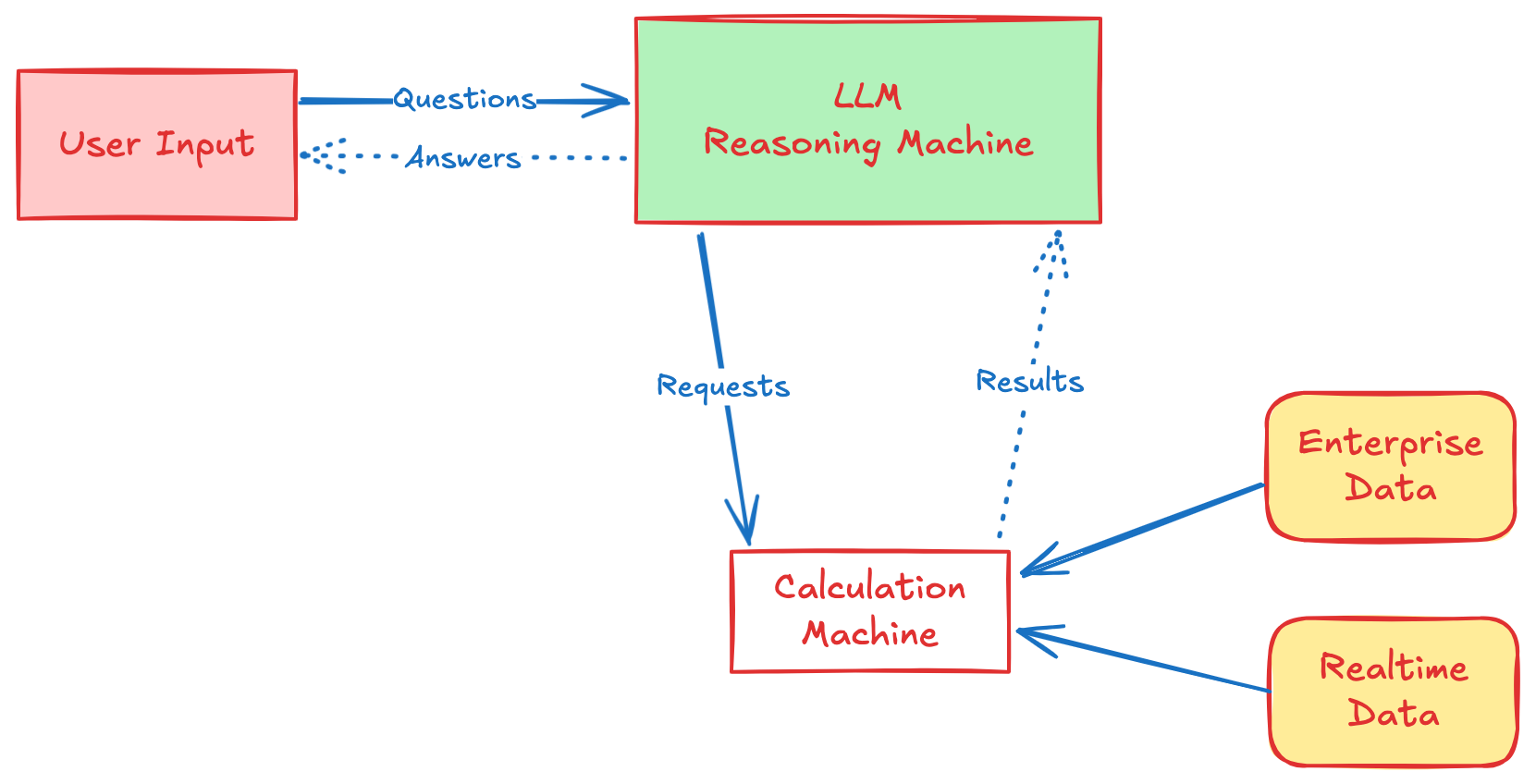
“推算分离”架构完美契合企业对大模型计算能力的四大核心诉求。
通过外部专业引擎执行计算,确保结果100%准确、可靠、一致,消除概率模型的不确定性。
计算错误清晰定位至LLM生成的数学表达式环节,易于诊断模型理解或推理偏差。
可针对性地通过微调、调整提示词等方式改进模型生成表达式的能力,快速修复问题。
响应速度快(平均2秒),Token消耗减半,成本可控,易于大规模部署,用户体验流畅。
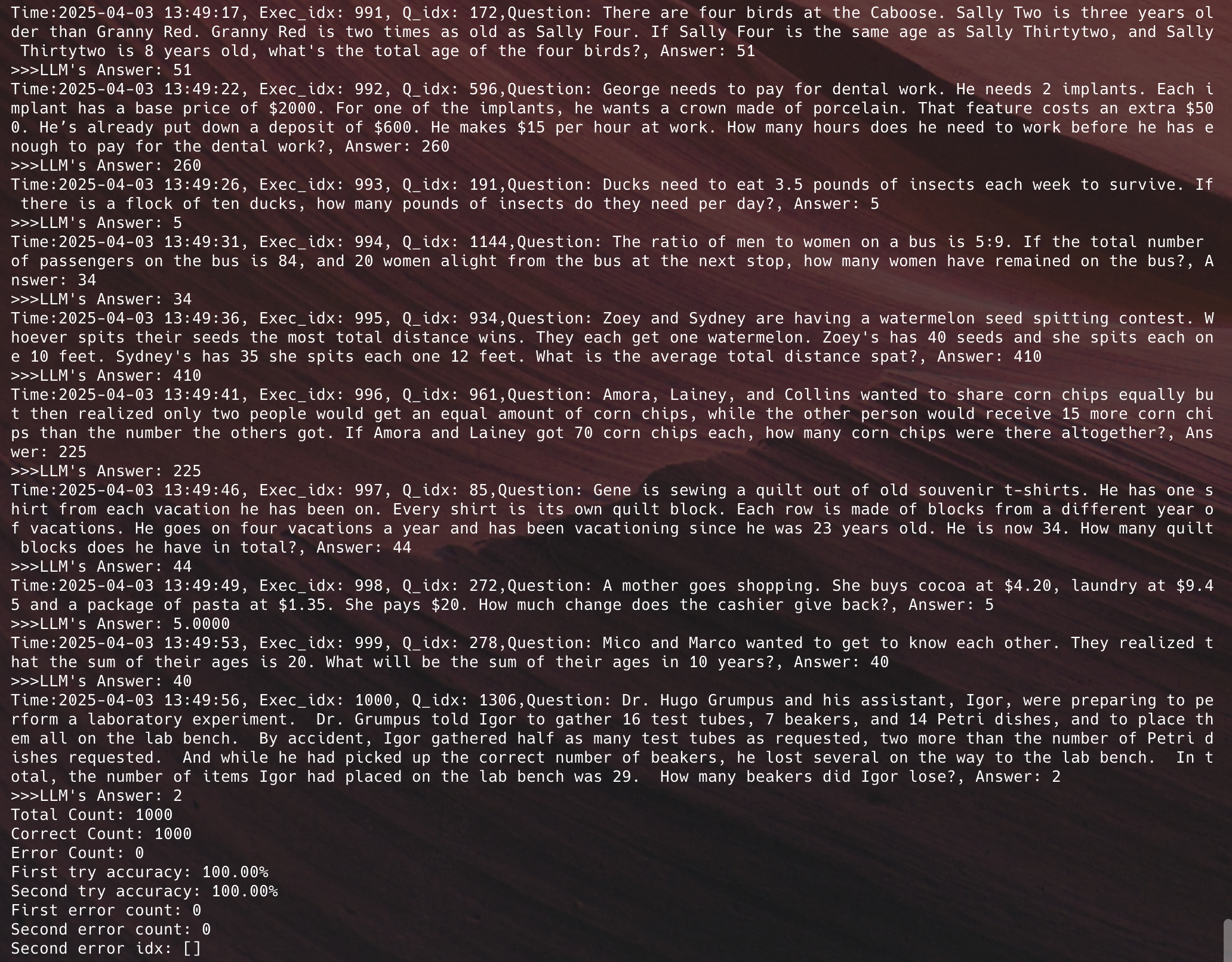
基于Qwen2.5-72B与本地专业计算引擎,我们在GSM8K测试中取得突破性成果。
>97% 单次输出正确率
>98% 二次输出正确率
人工调整后可达 100%
平均响应时间仅 2 秒
Token 消耗减少 50%
初等代数运算
矩阵运算
微分方程
卷积计算等
我们的技术正在为各行各业的关键业务提供动力,确保人工智能真正解决关键业务问题。